TL;DR:
Savanti is Cato Networks’ internal, agentic AI assistant that blends knowledge from Slack, Confluence, Git, and Jira to provide instant, context-rich answers. Savanti routes each query through an adaptive reasoning workflow by choosing between direct, deep, or multi-step reasoning based on the question’s complexity. Every answer is grounded in real internal context, backed by citations, and evaluated for confidence before being delivered. It’s not just RAG, it’s Agentic RAG: an AI that reasons, plans, and acts within its environment. This post shares how we built it, why it works, and what the agentic AI community can learn from the experience of deploying AI that actually helps engineers work faster and smarter.
Why We Built It
Where questions live, answers should too
Engineers ask questions where they collaborate in Slack. By embedding the assistant directly into Slack threads, we eliminated context switching and kept knowledge discoverable and transparent. Every answer is a small piece of shared documentation.
The reality of enterprise knowledge
Documentation lives across silos, design docs, tickets, PRs, tribal Slack wisdom. Savanti unifies these. Ask a question like “Why did we choose pgvector?”, and it retrieves the full story: the Confluence design doc, the Git PR, and the Slack thread where the tradeoff was decided. That’s context retrieval done right.
Why Agentic AI, not just search
Savanti doesn’t just retrieve, it reasons. Not every question deserves the same reasoning cost, so Savanti dynamically routes each query through the lightest reasoning path that can still deliver a high-confidence, well-cited answer. It uses planning steps, confidence checks, and structured tool use to decide when to answer, when to combine sources, and when to escalate to a human. This makes it as much an autonomous teammate as a search engine.
The Agentic Layer: Beyond Traditional RAG
Most RAG pipelines stop at “retrieve and respond.” Savanti adds an agentic reasoning loop:
- Plan: Parse intent, determine whether to search, synthesize, or escalate.
- Retrieve: Semantic vector search across multiple systems (Slack, Confluence, Git, Jira).
- Reason: Merge and validate context, check source agreement.
- Act: Reply with citations or suggest the best human contact if confidence is low.
Unlike linear RAG pipelines, Savanti can retry retrieval, switch reasoning strategies, or escalate to deeper analysis when confidence is low or sources conflict. This evaluation loop is what turns “pretty good” answers into reliable ones.
This reasoning cycle lets the assistant behave like a proactive collaborator rather than a static Q&A system. In Figure 1 we present a simplified overview architecture of Savanti.
Architecture
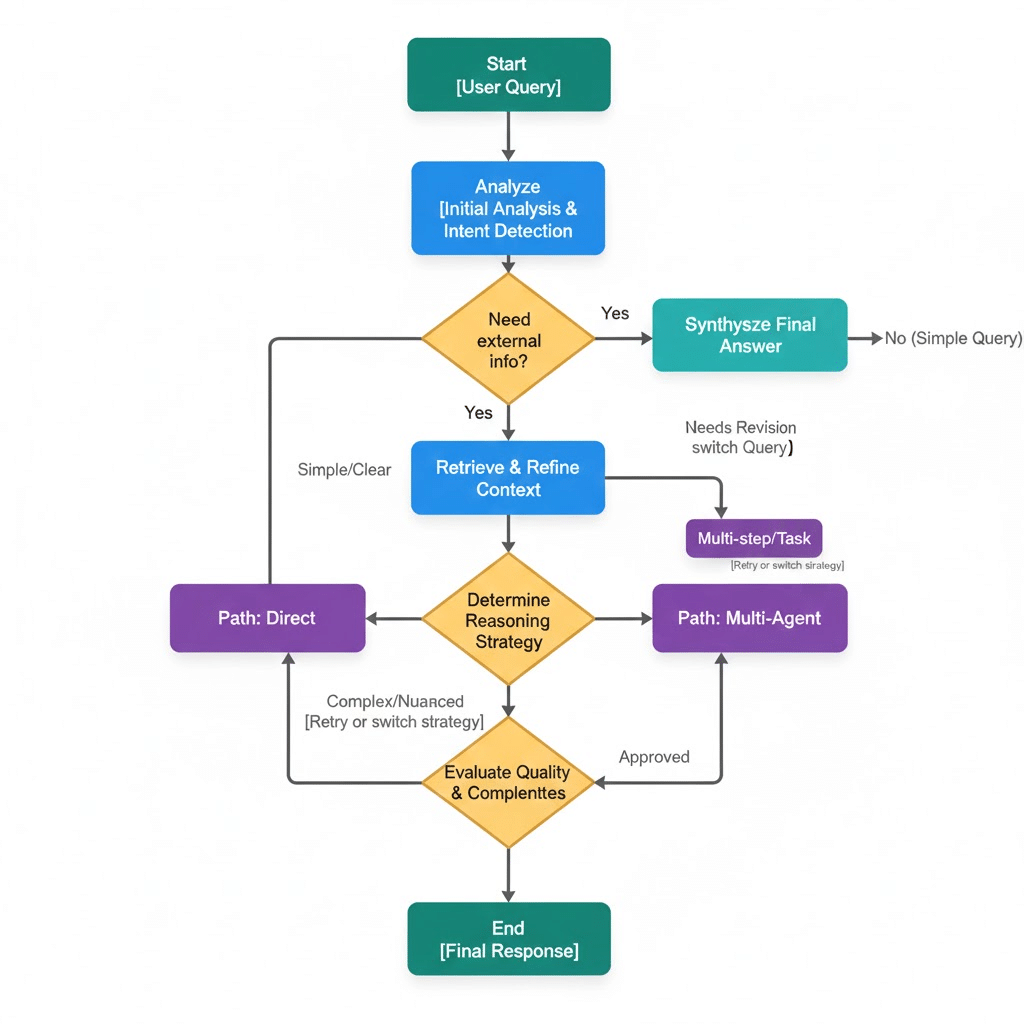
Figure 1: Savanti architecture
Design principles that matter
- Context-in / Context-out: Slack thread context enriches queries and allows the bot to answer in a shared, conversational tone.
- Unified knowledge graph: We built a multi vector RRF merging index that merges structured and unstructured knowledge from Slack, docs, code, and tickets.
- Persistence without complexity: Using Postgres with pgvector gives us durable, atomic updates and millions of searchable chunks without over-engineering.
- Citations-first: Every answer shows its sources, reinforcing trust and knowledge lineage.
- Adaptive routing: Queries are classified and routed to direct, deep, or multi-step reasoning paths based on complexity and confidence requirements.
- Deprecation-aware reasoning: When sources conflict or imply that guidance has changed, the assistant reconciles the evidence and compiles an up-to-date answer.
Real Impact on Developer Productivity
Even small context gaps waste time. Savanti fills those instantly:
- New hires ramp up faster without hunting for tribal knowledge.
- Engineers resolve blockers in minutes instead of hours.
- Better cross-team incident response. During on-call, it quickly brings the right context into the thread, helping teams converge on root cause with fewer handoffs.
We measured the impact qualitatively: fewer pings, faster resolution, and more “a-ha” moments when the agent connects threads humans forgot. Alongside qualitative feedback, we built internal monitoring to quantify adoption, citation quality, and estimated time saved per query.
Practical Examples of Savanti in Action
Configuration Discovery Example
The first example demonstrates how Savanti helps engineers resolve configuration-related questions by linking together relevant documentation, past discussions, and configuration guidelines. (Figure 2)

Figure 2: Savanti surfaces config details by linking relevant documentation and related team discussions.
Ownership Discovery Example
Savanti identified the right owner by confluence metadata and Slack context, even when names weren’t explicitly mentioned. (Figure 3)
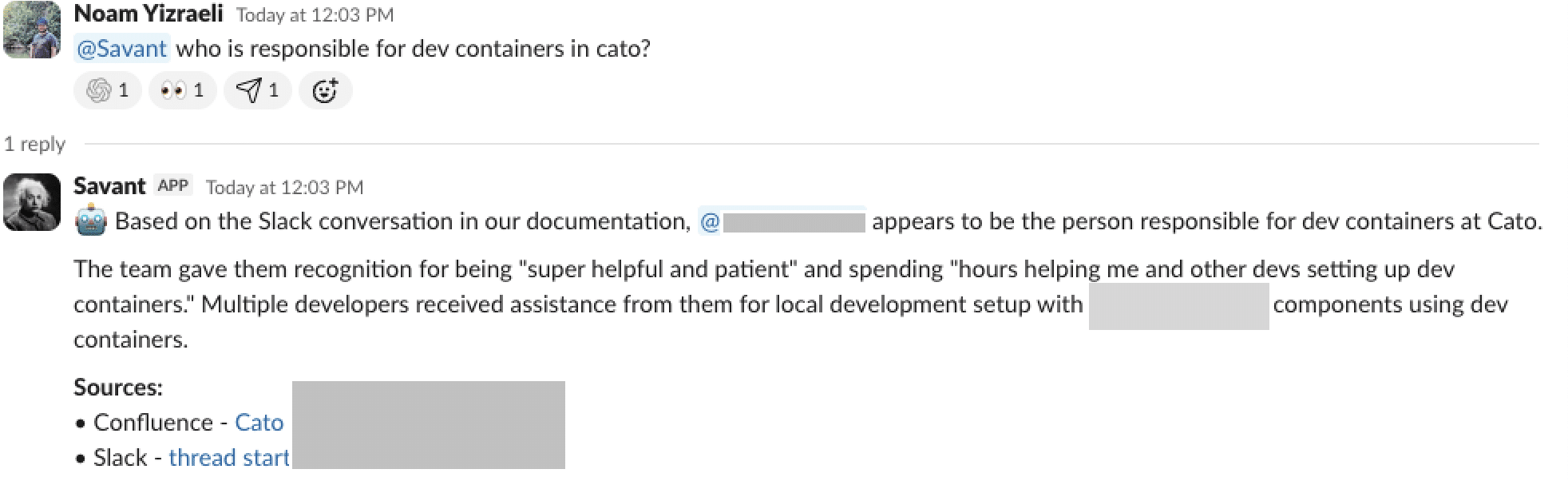
Figure 3: Savanti identifies the right owner by reasoning across Confluence metadata and Slack conversations.
Technical Decision Reconstruction Example
When engineers ask about past technical decisions or request guidance on a similar suggestion today, Savanti reconstructs the full reasoning behind the original choice. It surfaces design docs, Slack discussions, PRs, and related project history then asks clarifying questions to refine the answer (Figure 4), and provide more precise recommendations. (Figure 5).
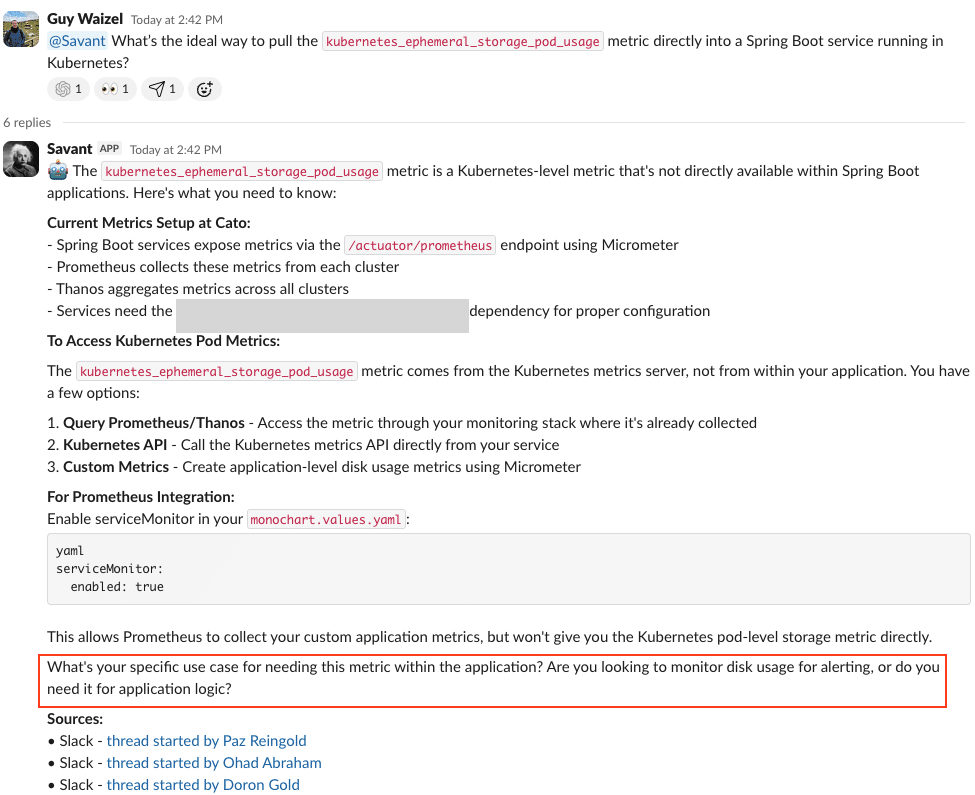
Figure 4: Savanti reconstructs past decisions to guide new technical choices

Figure 5: Savanti refines its answers using guided queries and structured reasoning
Each case is saving hours of human searching, but more importantly, it created a living, learnable institutional memory.
Monitoring and Statistics: Measuring Savanti’s Real Impact
Savanti’s success isn’t anecdotal, it’s measurable. We built an internal observability dashboard that continuously tracks its adoption, efficiency, and knowledge impact.
What We Measure
- Usage metrics: number of engineers, researchers, and product stakeholders actively querying Savanti.
- Time saved: each query is estimated to save ~15 minutes of manual search, reading, or coordination effort.
- Citation coverage: percentage of responses that include verified citations to Slack, Confluence, Git, or Jira.
- Knowledge amplification: indirect time savings for the people not interrupted: when engineers no longer need to be pinged for help, we estimate that the effect can be even a multiplier value by 5 or 10.
How We Visualize It
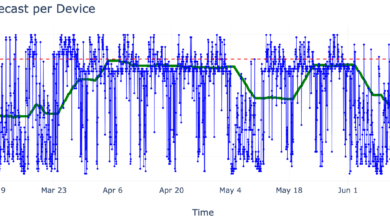
We visualize it with dashboard displaying the number of active users in the last 24 hours, citations per response, and total engineering hours saved. Each bar represents cumulative time reclaimed by autonomous, cited answers across Cato’s R&D teams.
The data confirms what we see culturally: Savanti doesn’t just save time per query, it compounds efficiency by freeing experts to focus on deep work while democratizing institutional knowledge. (Figure 6).
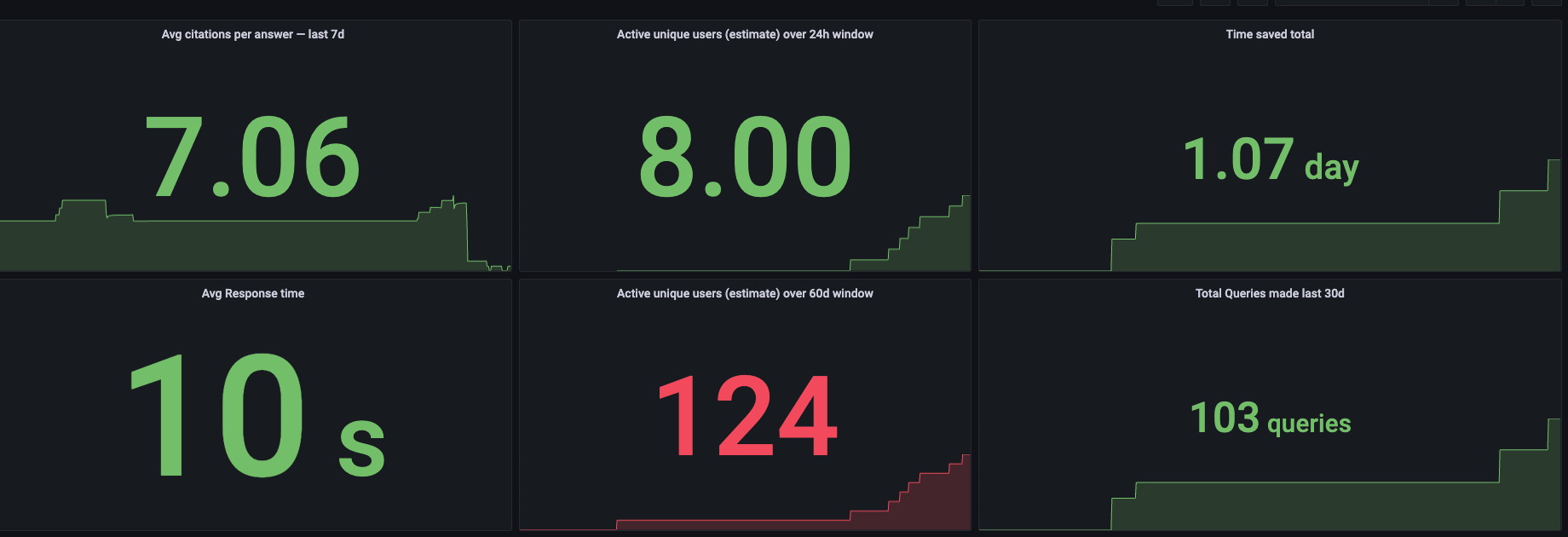
Figure 6: Savanti impact dashboard
What the Agentic AI Community Can Take Away
- Agentic RAG works: Blending reasoning with retrieval leads to materially better outcomes. It’s not just smarter search, it’s a reasoning agent living in the workflow.
- Public context matters: Placing AI where people collaborate amplifies its impact. Don’t build side-portals; embed intelligence in the flow.
- Keep it simple, then scale: Our MVP used a single Postgres instance and minimal glue code. Stability first, sophistication later.
- Measure quality, not vanity: We track latency, answer helpfulness, and confidence—not token counts or theoretical cost models.
- Routing is a product feature: Better UX often comes from doing less and using deeper reasoning only when it adds value.
Future Directions
We’re continuing to expand Savanti’s capabilities with:
- IDE and CLI integrations via a Model Control Plane (MCP)
- Smarter document enrichment and link-following
- Multi-prompt reasoning for complex questions
- Optional human-in-the-loop verification for critical answers
Our long-term goal: make every engineer’s environment a living, reasoning context engine that learns from interactions and feeds back insights across teams.
Why This Matters Beyond Cato
Savanti shows how agentic AI can boost not just productivity but culture, turning ephemeral chat into lasting, searchable knowledge. It demonstrates a pattern any modern engineering org can adopt: Embed reasoning agents where collaboration happens, ground them in real context, and let them evolve alongside your knowledge.
For developers and AI practitioners, the lesson is clear: RAG is only the foundation. True leverage comes when your AI agents think, reason, and act within your workflows.
The post Savanti: How Agentic AI Supercharge Cato’s R&D Efficiency appeared first on Cato Networks.