Resilient by Design: Cato’s Visibility and Backbone Performance Through the AWS Outage
Maintaining Continuity and Visibility Through the October 2025 AWS Outage
On October 20, 2025, Amazon Web Services (AWS) experienced an outage affecting its US-East-1 region. The event caused temporary service degradation across a wide range of global applications and digital services, including business collaboration tools, financial platforms, airline operations, and consumer-facing websites used by millions of people worldwide, as reported in the news. We extend our appreciation to our partners at AWS for their swift and professional handling of the incident.
The outage once again highlighted why owning the underlying infrastructure matters. When a hyperscaler backbone fails, as seen during the recent Google Cloud outage, the ripple effects can be felt across the internet. In contrast, Cato Networks’ customers maintained service continuity with minimal impact, demonstrating the resilience of our privately owned global backbone and distributed PoP architecture. Together, these components provide robust connectivity and full visibility, even amid large-scale cloud disruptions.
A Cloud Event That Tested Global Connectivity
According to the AWS Health Dashboard, the outage affected several AWS services in the US-East-1 region, resulting in elevated error rates and connectivity issues. For many organizations relying heavily on cloud-hosted applications, the event temporarily disrupted collaboration, file sharing, and business operations.
Cato Networks observed these effects from our global vantage point, not as interruptions in our own infrastructure, but as SaaS-layer degradation visible through our Cloud Application Analytics.
What Cato Observed During the AWS Event
As shown in Figure 1, we observed a sharp surge in error rates across multiple AWS-hosted SaaS applications during the outage window, highlighting how service availability dropped simultaneously across several platforms. In Figure 2, the HTTP failure rate for Slack based on real user traffic provides a concrete example, showing a clear spike at the exact time of the AWS disruption before normalizing as services recovered.
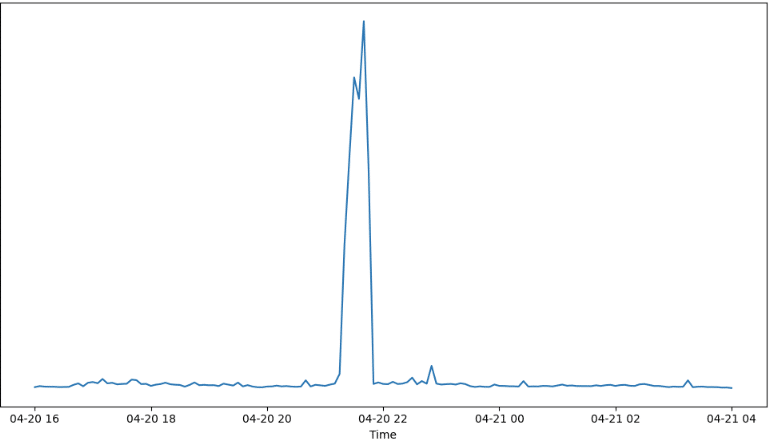
Figure 1. Error rate over time for major SaaS applications hosted on AWS — note the sharp spike corresponding to the October 20 AWS outage.
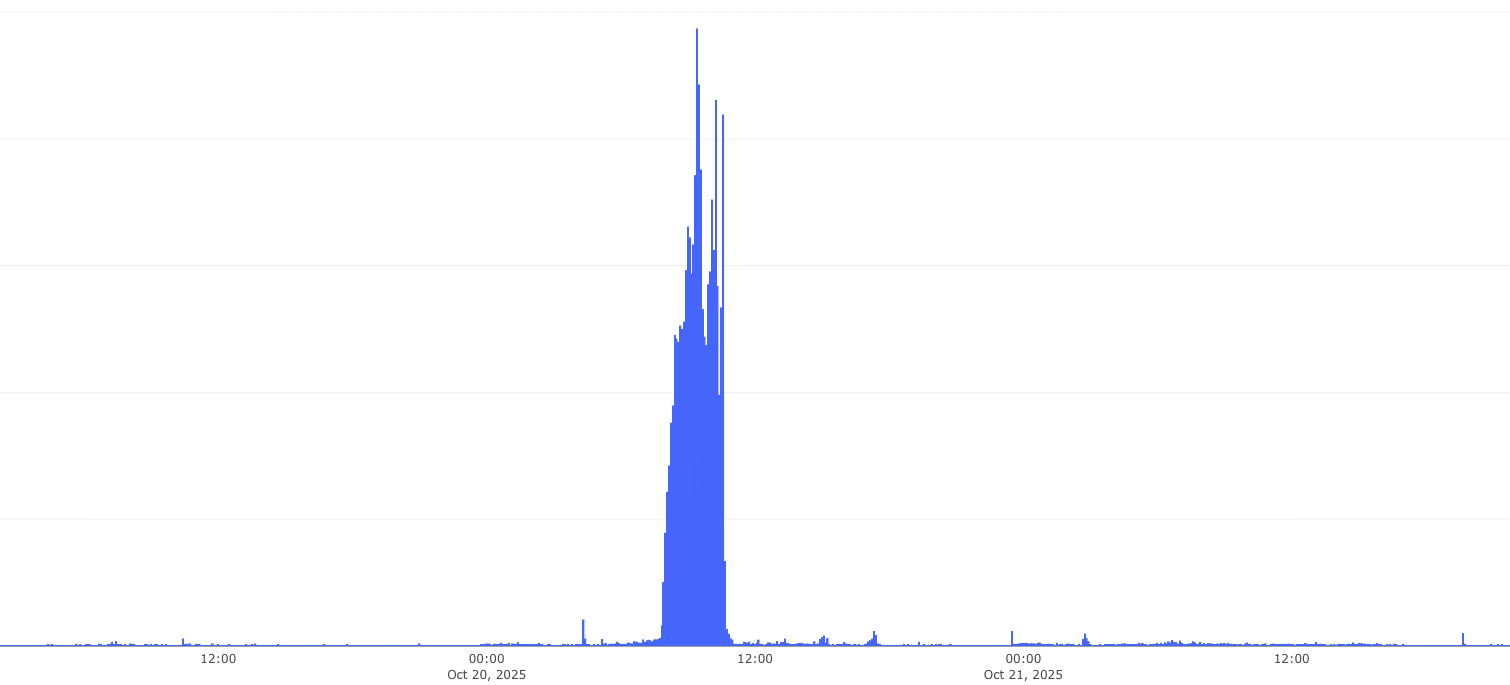
Figure 2. Sum of HTTP failures for Slack over time — the spike aligns precisely with the AWS service disruption window.
Even as connectivity issues surfaced across the Internet, Cato’s backbone and PoPs maintained 100% availability. Customers could see in real time that network transport was healthy while specific SaaS destinations were degraded, providing a level of clarity rarely possible in traditional architectures.
From Cato’s real-time analytics platform, we detected:
- Noticeable drops in usage for SaaS applications hosted on AWS during the AWS incident window
- Stable network latency, throughput, and packet delivery across Cato PoPs, confirming that our backbone remained unaffected
Customers using the Cato Management Application could clearly distinguish between SaaS service impact, which was external, and network performance, which remained fully operational.
This visibility empowered IT and NOC teams to focus their efforts correctly, reduce noise, accelerate troubleshooting, and maintain confidence in their infrastructure throughout the outage.
In Figure 3, we show how customers can observe HTTPS and HTTP error rates over time directly within the Cato Management Application, allowing them to monitor service-level degradations in real time.
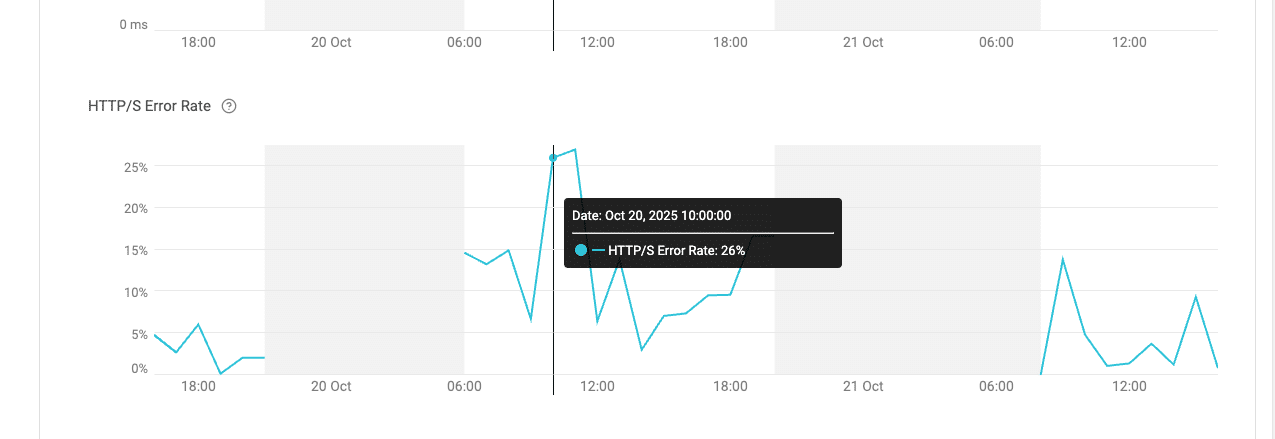
Figure 3. HTTPS and HTTP error rates over time as seen in the Cato Management Application — highlighting increased SaaS-layer failures during the AWS outage.
In Figure 4, the Site Application Experience Score demonstrates how performance for Amazon AWS noticeably declined during the incident window compared to other SaaS applications, visualizing the event’s impact on the user experience layer.
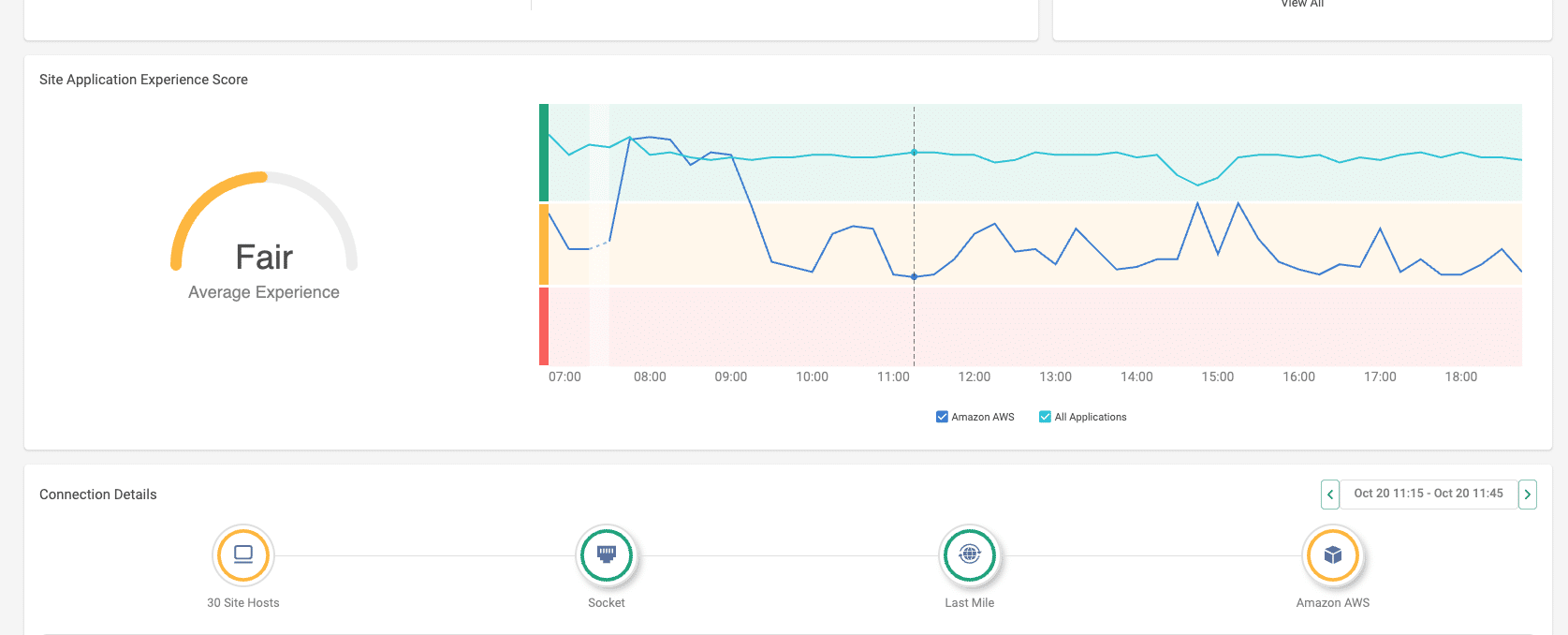
Figure 4. Site Application Experience Score comparison showing decreased performance for Amazon AWS relative to other SaaS applications during the outage period.
Why Cato Stayed Strong: Architecture Built for Continuity
Cato’s architecture is designed to remain resilient and cloud independent. Even when hyperscale regions experience challenges, our SASE platform continues operating seamlessly. But hyperscale independence isn’t the only reason why Cato can deliver on a 99.999% uptime SLA.
Separation of Control and Data Planes
The control plane and data plane operate independently. This ensures the management layer remains functional even if a data transport path encounters instability, and vice versa.
Distributed PoP Architecture
Cato’s Points of Presence (PoPs) are independently operated and maintained by Cato. All running Cato’s fully distributed software stack. With PoPs in 85+ locations, is not tied to any single cloud region or provider. If one PoP becomes unreachable, traffic automatically routes through the nearest available node in our private backbone, keeping sessions active and performance stable.
Automatic WAN Recovery
When connectivity anomalies occur, WAN Recovery activates instantly without manual intervention. Cato Sockets automatically reconnect through available alternative links to preserve site-to-site and internet access. Local firewall policies remain active, and internal site operations continue normally, even if one upstream path is impaired.
Multi-Layered Failover
Resilience is built into every layer of Cato’s stack:
- Socket High Availability (HA) enables automatic switching between primary and secondary Sockets.
- WAN Recovery seamlessly fails over to an alternate connection, such as a secondary ISP link or LTE backup, in the event of a line outage—maintaining site connectivity without manual intervention.
- Internet Recovery temporarily reroutes traffic through local ISP paths if a PoP becomes unreachable.
- A back-off algorithm intelligently manages reconnection attempts to prevent instability during recovery.
Multi-Path Cloud Resilience: Cato’s HA, BGP & BFD in Action
Cato offers multiple cloud-connectivity options that can help enterprises maintain operations and avoid single-path dependency during large-scale cloud incidents. These capabilities are part of Cato’s strategy for resilient, cloud-agnostic connectivity, a strength that recently earned the company recognition in Gartner’s Market Guide for Private Connectivity to Public Cloud Services (subscription required).
1. Native High Availability with Cato vSocket
Enterprises deploying Cato vSockets inside AWS can configure them in High Availability (HA) mode across multiple Availability Zones or even regions. If one path or zone experiences degradation, traffic can automatically fail over to the standby vSocket, maintaining session continuity and business continuity for connected workloads – without manual intervention.
2. Software-Defined Cloud Interconnect (SDCI) with BGP and BFD
For inter-region or hybrid deployments, Cato’s Software-Defined Cloud Interconnect supports both Border Gateway Protocol (BGP) and Bidirectional Forwarding Detection (BFD).
This combination enables sub-second failure detection and rapid route re-convergence between regions.
For example, if AWS US-East-1 experiences instability, traffic can seamlessly reroute to another region such as EMEA, helping maintain connectivity, uptime, and performance for critical cloud-hosted services.
Outcome: Continuous Operations and Visibility
These capabilities enable organizations to:
- Detect failures quickly and reroute traffic to healthy regions
- Preserve service continuity and minimize user impact during cloud disruptions
- Maintain full visibility through the Cato Management Application, distinguishing SaaS-layer degradation from backbone performance
Learn more: Getting Started with Cloud Interconnect Sites and Configuring BFD for BGP Neighbors
Real-Time SaaS Visibility: Seeing What Matters Most
During the AWS outage, visibility made all the difference. While many IT teams struggled to identify the source of disruptions, Cato customers had clear insight into application-layer health.
Through Cato’s Application Analytics, IT teams could:
- Identify which SaaS services were impacted by the AWS outage
- Validate that the Cato backbone remained fully operational
- Communicate accurately with users about external service degradation
This visibility transformed a global cloud incident into a manageable network event. Cato customers stayed connected, informed, and confident in their operational stability.
The Final Lesson: Architectural Independence is Key
The October 2025 AWS US-East-1 outage reinforced an important lesson for enterprises: cloud resilience requires architectural independence, visibility, and automation.
Key takeaways for IT leaders:
- Design for independence by avoiding reliance on a single region or backbone
- Build visibility into your network to separate internal issues from external disruptions
- Automate failover through BFD, BGP, and layered redundancy
- Use intelligence to adapt dynamically before users notice a problem
We are proud to complement the reliability of cloud partners like AWS with an independent, intelligent backbone that ensures continuity and clarity when the unexpected occurs.
With AWS’s swift mitigation efforts and Cato’s distributed SASE backbone, our customers stayed connected and aware, with services operating smoothly and full visibility into SaaS performance throughout the event.
Resilience is not only about surviving disruption. It is about understanding it, responding intelligently, and continuing to deliver.
The post Resilient by Design: Cato’s Visibility and Backbone Performance Through the AWS Outage appeared first on Cato Networks.


