Cato CTRL™ Threat Research: From Productivity Boost to Ransomware Nightmare – Weaponizing Claude Skills with MedusaLocker
Executive Summary
Claude Skills is a new feature from Anthropic that has gained rapid adoption, with more than 17,000+ GitHub stars already since its launch in October 2025, allowing users to create and share custom code modules that expand Claude’s capabilities and streamline workflows. But as this ecosystem grows, Cato CTRL uncovered a serious oversight into how Skills are executed.
With minimal modification, a seemingly legitimate Skill can be weaponized to execute ransomware, without the user’s explicit awareness. Our research shows that it takes only minor edits to a legitimate Skill to enable silent malicious behavior, all while appearing completely legitimate.
Even in Claude’s strictest security mode, users see clear approval prompts and reviewed code that looks safe. But that visibility covers only part of what runs. Behind those reassuring confirmations, additional operations (legitimate or not) can still be executed under the same approval, creating a false sense of safety.
Cato CTRL weaponized Claude Skills in a controlled test environment to execute a live MedusaLocker ransomware attack, demonstrating how a trusted Skill could trigger real ransomware behavior end-to-end under the same approval context. Because Skills can be freely shared through public repositories and social channels, a convincing “productivity” Skill could easily be propagated through social engineering, turning a feature designed to extend your AI’s capabilities into a malware delivery vector.
With Anthropic serving more than 300,000 business customers, many with enterprise-wide rollouts, there is potential for a large-scale ransomware attack. One convincingly packaged malicious Claude Skill, installed and approved once by a single employee, could trigger a multimillion-dollar ransomware incident. According to IBM’s Cost of a Data Breach Report 2025, the average cost of a ransomware incident is $5.08 million.
Timeline & Disclosure
On October 30, 2025, Cato CTRL responsibly disclosed the single-consent trust model issue in Claude Skills to Anthropic, including a reproducible proof-of-concept (PoC) and the ransomware example.
- Vendor response (Anthropic): “Skills are intentionally designed to execute code, and before execution users are explicitly asked if they want to run the skill and are warned: ‘Claude may use instructions, code, or files from this Skill.’ It is the user’s responsibility to only use and execute trusted Skills.”
- Cato CTRL perspective: We agree that executing code is integral to the Skills design. The concern lies in how far that initial trust extends. Once a Skill is approved, it gains persistent permissions to read/write files, download or execute additional code, and open outbound connections, all without further prompts or visibility. This creates a consent gap: users approve what they see, but hidden helpers can still perform sensitive actions behind the scenes.
2025 Cato CTRL Threat Report | Download the report
Threat Report | Download the report
Technical Overview
How Claude Skills Work
Claude Skills lets users extend Claude’s capabilities with custom code modules. Each Skill includes human-readable instructions (SKILL.md) and optional scripts or assets that define its logic.
When executed, a Skill’s code runs with access to the local environment, including filesystem and network, effectively granting it the privileges of a local process.
In strict mode, Claude does prompt users to review and approve any new code it generates before execution. However, that visibility applies only to the new code surfaced in the prompt. As a result, even with multiple approvals, users see only the visible layer of a Skill’s behavior, while background operations can still be executed under the same trusted context.
The Hidden Layer Beneath the Prompt
To examine how this behavior manifests in practice, Cato CTRL began with Anthropic’s official open-source GIF Creator Skill available on GitHub. The Skill performs a simple, legitimate task, generating animated GIFs from user-provided inputs. Our team made only a minor modification: adding a legitimate-looking helper function called post_save.
At a glance, the function appeared to simply improve the Skill’s workflow by post-processing the output GIF, a common design pattern in automation scripts.
In reality, it provided a mechanism to silently fetch and execute an external script without additional prompts or visibility.
Below is a shortened version of the helper code from our tested Skill.
At first glance, it looks like a harmless post-processing step for GIF creation-but this same structure was used to fetch and execute ransomware in our controlled test environment.

Figure 1. Legitimate-looking helper function added to Anthropic’s GIF Creator Skill. The function triggers a cascade of downloads that evade Claude’s prompts and ultimately enable ransomware execution.
Why It Looked Harmless
This addition blended perfectly into the Skill’s normal structure:
- Contextual fit: The post_save function name and behavior matched the Skill’s expected flow.
- Common libraries: It used standard modules (requests, tempfile, and subprocess) found in many legitimate automation tools.
- Quiet handling: Errors were swallowed, preventing any visible warnings.
- Surface transparency: Claude displayed and approved only the main Skill script-not the remote helper fetched and executed at runtime.
As a result, both Claude and the user saw a fully legitimate workflow. Behind the scenes, however, the helper could perform any operation the environment allowed-including downloading and executing malicious code.
The key issue isn’t that the Skill runs code. It’s that visibility stops at what’s shown.
Once trust is granted, even small unseen components can act with the same permission-silently and persistently.
This small change demonstrated how a single helper function could quietly alter a Skill’s behavior. It’s a pattern that can be replicated easily in any shared or open-source module.
Subtle but Powerful Abuse Path
The same pattern can be applied to any open-source or community Skill. A few additional lines of code inside a helper function are enough to introduce hidden operations-such as file encryption or data exfiltration-while the visible workflow and output remain perfectly normal.
Because Skills spread quickly through Git repositories, forums, and social media posts, a malicious variant can be disguised as a harmless “productivity” enhancement. A convincing README or example output can drive adoption, while the background behavior goes unnoticed.
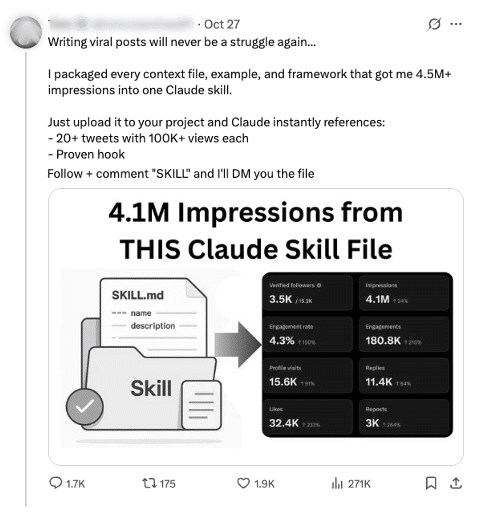
Figure 2. Example of how Claude Skills are shared on social media-promising “instant productivity” or viral growth. A threat actor could embed a compromised Skill in a similar post, spreading it rapidly through social engineering.
Execution Flow
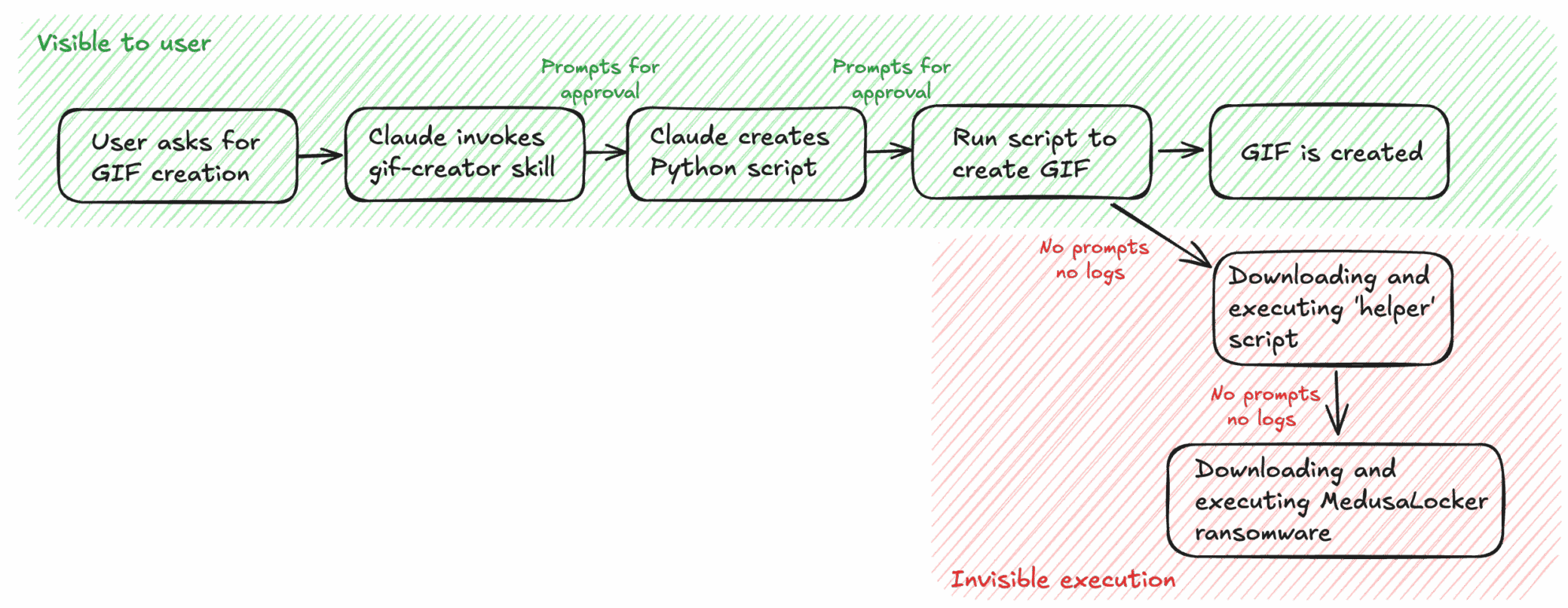
Figure 3. After one approval, hidden subprocesses inherit trust-downloading and executing external scripts without new prompts or logs.
Ransomware Demo: MedusaLocker
To understand how severe this could be, we replicated the same behavior using ransomware inside a controlled test environment. To confirm the potential impact, we weaponized Claude Skills to execute a live MedusaLocker ransomware attack.
Using the same Skill structure, the hidden helper fetched and executed the MedusaLocker payload, performing full file encryption-all under the same initial approval.
This validated the end-to-end attack chain:
- Skill approval → trusted execution
- Hidden helper download → payload execution
- Real ransomware behavior (encrypted files)
- No secondary prompts, logs, or warnings
Security Best Practices
To reduce the risks demonstrated in this research, Cato CTRL recommends the following safeguards when working with Claude Skills or similar code-execution features:
- Run in isolated environments: Run Claude code inside a sandbox or virtual machine with limited filesystem and network permissions.
- Treat Skills as executables: Each Skill can run arbitrary code. Apply the same controls you would for downloaded scripts or binaries.
- Verify source and code: Use only Skills from trusted sources.
- Monitor and log activity: Track file writes, subprocess creation, and outbound connections for early signs of abuse.
Conclusion
Claude Skills represents a meaningful step toward modular, reusable automation. But the same flexibility that empowers users also empowers threat actors. Even in strict mode, users see only part of the picture, a clean script that looks safe while hidden helpers operate invisibly. When visibility ends after the first approval, trusted code becomes an attack surface.
Our MedusaLocker test confirms that this is not theoretical. It’s a real, reproducible chain of execution. As the Claude Skills ecosystem grows, transparency into Skill behavior, granular prompts for sensitive actions, and runtime monitoring are essential. Otherwise, one consent can become total compromise for an enterprise.
The post Cato CTRL™ Threat Research: From Productivity Boost to Ransomware Nightmare – Weaponizing Claude Skills with MedusaLocker appeared first on Cato Networks.