Gradual by Design: What the Cloudflare Outage Reveals About Robust SASE Architecture and Operations
On November 18, 2025, a single configuration file change at Cloudflare disrupted access to large parts of the web.
Around 11:20 UTC, Cloudflare’s network began returning a surge of HTTP 5xx errors. Users trying to reach services like X (formerly Twitter), ChatGPT/OpenAI, Ikea, Canva, and many others suddenly saw Cloudflare-branded error pages instead of the applications they expected. Cloudflare mitigated the issue, restored service, and published a detailed public report.
The outage might have impacted the general market, but it carries important lessons for anyone considering a SASE deployment. Network and security architecture-along with the operational practices behind them-directly shape service delivery and continuity. Incidents are inevitable, but their impact can and should be contained. And when they do occur, the Cloudflare outage underscores the need to give customers clear visibility and control so they can quickly understand what’s happening, which applications and users are affected, and what actions to take.
A Very Short Recap of the Cloudflare Incident
Cloudflare’s blog post walks through the incident in detail, in brief: A database permissions change caused the query that generates a Bot Management “feature” file to behave differently, making the file larger than expected and exceeding a limit in Cloudflare’s traffic engine. Because this file is refreshed every few minutes and pushed globally, the malformed version quickly triggered widespread HTTP 5xx errors across Cloudflare-frontend services until Cloudflare stopped its propagation and rolled back to a known-good file.
The operational lesson is clear: Pushing a network change too quickly across a global platform risks interfering with service delivery. This is exactly why gradual rollout, guardrails, and easy rollback are core design principles for the Cato SASE Platform. In the following sections, we’ll focus on how these principles are applied across our platform, PoPs, Sockets, clients, features, and especially feeds, and why that matters in the context of an incident like Cloudflare’s.
SASE Champion’s Playbook | Download the eBook
What We Do in Cato to Keep One Bad Change from Becoming an Outage
At Internet scale, the most dangerous phrase in operations is: “Let’s push it everywhere.” Our answer: every change is gradual, monitored, and reversible.
Gradual Rollout Across the Platform
Our public article Understanding Rollout to the Cato Cloud explains this model. We roll out changes incrementally in controlled stages across our network:
- Cato Cloud (PoPs & Management Plane): PoPs are updated on a bi-weekly schedule, with content rolled out over ~two weeks, PoP by PoP. The management application is updated weekly, but new features and capabilities are activated gradually across accounts.
- Sockets & Clients: New versions are deployed in phased cohorts, starting with small groups of sites or users and expanding only if health signals look good.
The result: no single version or change ever lands on 100% of PoPs, sites, or endpoints at once.
Features and Feeds: Fast, but Still Gradual
We do something similar for new features (capabilities) and security and policy feeds:
- Features: New capabilities are enabled with staged activation (internal testing, select customers or regions, and then wider rollout), with central controls to deactivate quickly, if needed.
- Feeds: Security and policy feeds (indicators, signatures, models, and configuration content) must be updated quickly but still need to be rolled out in controlled steps, with central monitoring for errors and anomalies, and rollback and freeze if a feed misbehaves unexpectedly.
Whether it’s a major rollout, like a new feature, or a minor change, such as an update to a security feed, everything is introduced gradually, monitored centrally, and safeguarded with rollback and freeze controls to prevent a faulty update from creating a widespread outage.
Watching Propagation, Not Just the End State
We don’t only look at “Is it working now?” We track how each change moves across our platform. Feature and feed changes are deployed through a well-designed cycle of gradually increasing exposure to limit the impact on production customers. A change will go through Continuous Integration / Continuous Delivery (CI/CD) and then Early Availability (EA) for limited PoPs or customers, and finally into General Availability (GA). Each stage has specific health gates that must be met before being promoted to the next stage. The promotion is also driven by telemetry, rather than being artificially scheduled by a calendar. In short, propagation itself is a signal we watch to decide whether to advance, pause, or roll back.
Rollback and Guardrails Built In
Rollback is designed in, not improvised:
- Every change has a defined rollback path.
- PoP, Socket, and Client rollouts can revert if issues appear.
- Central controls let us disable a problematic component or feed quickly.
On top of that, widely distributed artifacts are subject to limits and validation (for example, size and structure checks) before rollout, reducing the risk that a single misconfigured file can trigger a broad impact.
A SASE Architecture Designed for Resiliency
Cato runs a global private backbone of PoPs that replaces the public Internet for customer traffic. Each PoP runs our Single Pass Cloud Engine (SPACE), converging networking and security (SWG, CASB, ZTNA, FWaaS with advanced threat prevention, etc.) into a single software stack.
Key resiliency benefits:
- A self-healing backbone that continuously measures latency, loss, and jitter and routes around problems
- Scale-out, high availability, so local issues don’t become global outages
- Unified policy and visibility, showing the full path from user to application
During an event like the Cloudflare outage, this architecture acts as a shock absorber: routing around impacted regions where possible, keeping unaffected apps optimized, and giving you clear, actionable visibility into what’s happening, where, and to whom.
What We Saw: Instant Visibility into the Outage
When a big provider stumbles, IT teams always ask the same question first:
“Is it us, our SASE platform, or something upstream like the internet, Cloudflare or the application provider?”
Because Cato converges networking, security, and digital experience monitoring, our customers could answer that quickly on Nov 18. In Figure 1, we see a sharp spike in HTTP errors to OpenAI during the incident, while WAN paths and other SaaS apps remain healthy, clearly indicating an upstream application/provider problem, not a Cato or customer network issue.
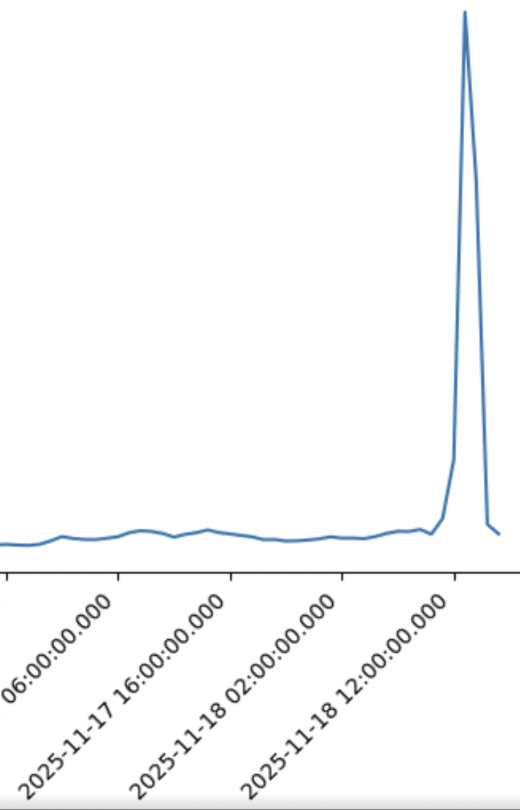
Figure 1. HTTP failures observed for OpenAI during the time of the incident
The Cato Management Application then adds a digital experience view that shows where, who, and how users are impacted. Figures 2 and 3 illustrate this for ChatGPT and X.com, with HTTPS errors and experience scores by site and user group.
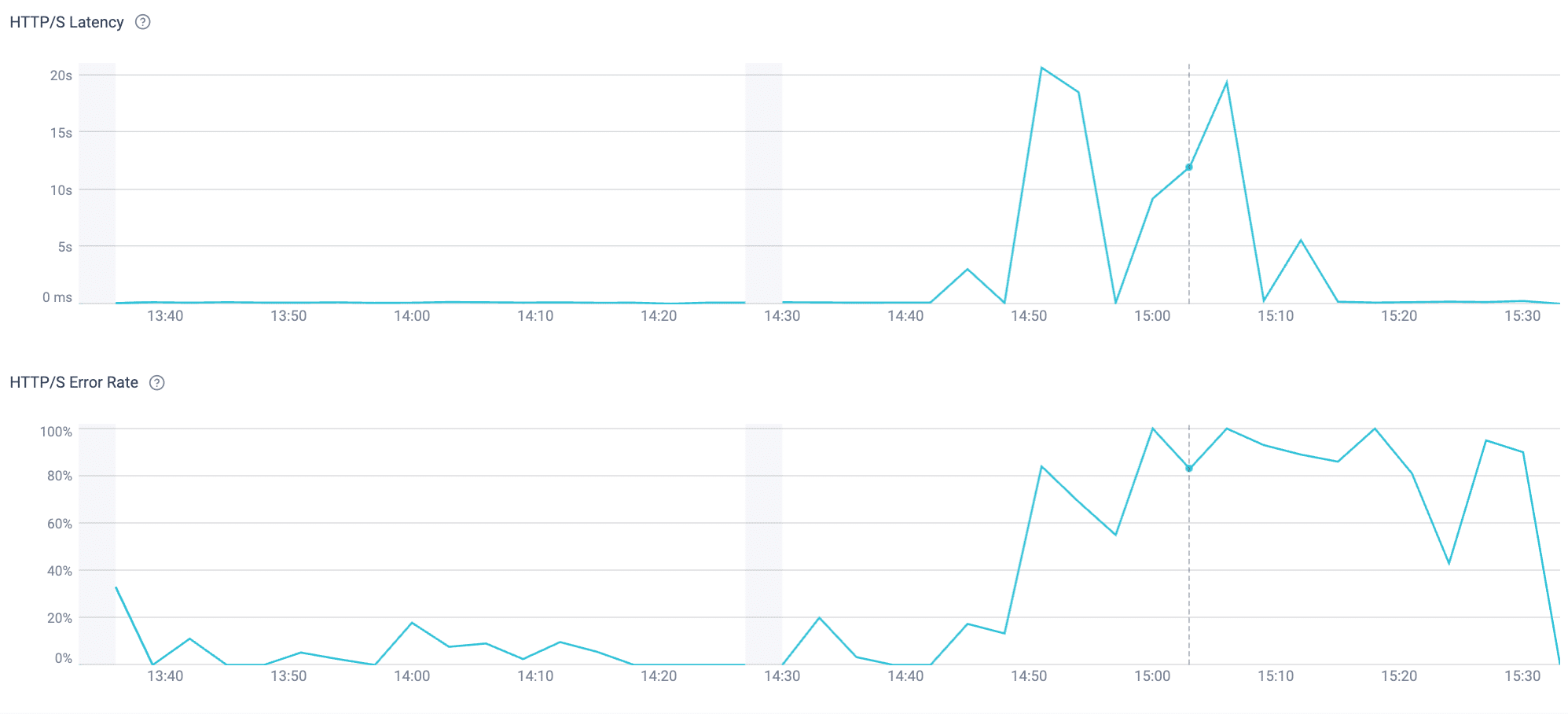
Figure 2. HTTPS failure monitoring for ChatGPT from the Cato Management Application
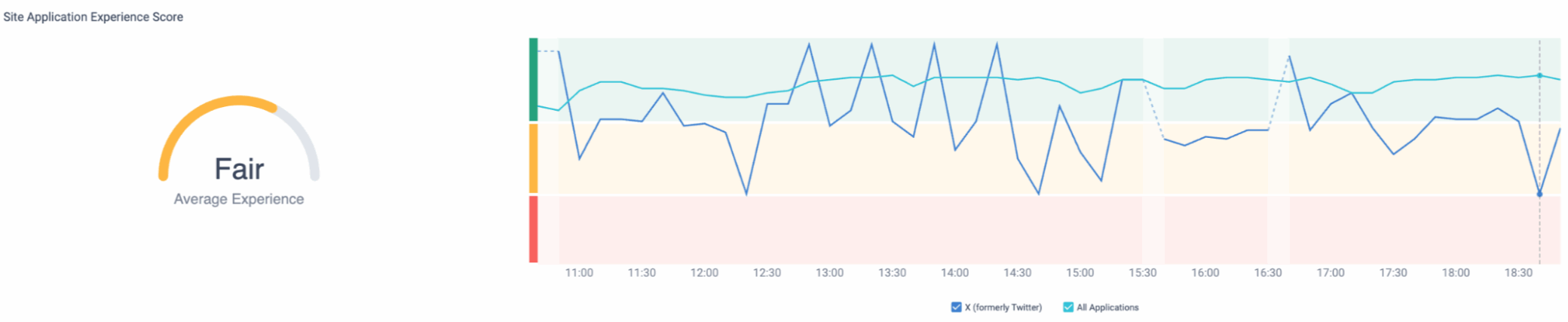
Figure 3. Average experience score for X.com, showing degradation
Instead of just hearing “ChatGPT is down,” IT can immediately see which apps are affected, which are fine, and that this specific incident is Cloudflare-related and upstream, all backed by data.
Incidents Happen, But You Can Still Be In Control
Cloudflare’s Nov 18 outage is another reminder of a broader reality: the entire industry depends on a small number of critical cloud providers, and those providers rely on centralized configurations and rapidly updated, ML-driven artifacts. When a latent bug enters that pipeline, the consequences can be widespread.
At Cato, we architect our platform to prevent similar large-scale outages on our network by building safety and resilience into every stage of change management:
- Gradual deployment, ensuring no update reaches the entire network at once.
- Propagation monitoring, allowing us to halt a bad change before it spreads.
- Built-in rollback, with clear, tested procedures to restore service quickly and minimize disruption.
- Pre-production validation and strict guards on global artifacts to minimize the likelihood of an incident.
- A resilient SASE backbone and deep end-to-end visibility so you know exactly which apps, users, and sites are affected
And when outages occur outside our network, we help reduce their impact and keep you in control-no matter what’s happening upstream.
The post Gradual by Design: What the Cloudflare Outage Reveals About Robust SASE Architecture and Operations appeared first on Cato Networks.